2001 年にリリースされた TA-Lib, Technical Analysis Library は、150 以上のテクニカル指標をサポートしていて、長年にわたる検証を経ています。現在の Python 用パッケージは、Cython と Numpy を用いて効率的かつクリーンに TA-Lib をバインドしています。TA-Lib は BSD License (BSD-2-Clause license) の元で配布されているオープンソースのライブラリです。
株価の値動きなどを分析する際に TA-Lib のパッケージを利用していますが、デイトレ用のリアルタイム・システムで利用しようとすると、ちょっと扱いにくいと感じていました。それは、TA-Lib では全てのデータ列に対して計算するからです。そのため、リアルタイムの処理では専用の処理をするクラスを用意して対応しているのですが、計算負荷を少なくするための検討は結構面倒な作業です。
Github の TA-Lib / ta-lib-python プロジェクトサイトにある README をよく読むと、実験段階ながら Streaming API が提供されていることがわかりました。
詳細なベンチマークテストをしていませんが(下に追記しました [2026-03-12])、リアルタイム風に動作するサンプルを作ったので紹介します。
下記の OS 環境で動作確認をしています。

|
Fedora Linux 43 |
x86_64 |
| Workstation Edition |
| Python |
3.14.3 |
| numpy |
2.4.3 |
| pandas |
3.0.1 |
| pyqtgraph |
0.14.0 |
| pyside6 |
6.10.2 |
| ta-lib |
0.6.8 |
TA-Lib の Streaming API とは
従来の API は、過去データ全体に対してインジケーターを計算する設計です。
import numpy as np
import talib as ta
# 過去のデータ全体を一度に処理
prices = np.array([100, 101, 102, 103, 104, 105], dtype=float)
ma = ta.SMA(prices, timeperiod=3)
# 結果:
print(ma)
[ nan nan 101. 102. 103. 104.]
Streaming API は、直近のデータウィンドウに対してインジケーターを計算します。
import numpy as np
from talib import stream
# 新しいデータポイントが到着するたびに計算
buffer = np.array([100, 101, 102], dtype=float)
ma = stream.SMA(buffer, timeperiod=3)
print(ma)
# 次のデータが到着
buffer = np.array([101, 102, 103], dtype=float)
ma = stream.SMA(buffer, timeperiod=3)
print(ma)
101.0
102.0
Streaming API の主な特徴
- 固定長バッファで動作
- 計算に必要な期間(例:30 期間)のデータのみを保持
- メモリ効率が良い
- 最新値のみを返す
- 従来の API は配列全体を返すが、Streaming API は単一の値を返す
- Streaming API は、渡された配列全体に対してインジケーターを計算し、最後の値だけを返す関数です。つまり 1000 個のデータを渡せば 1000 個分の計算をしてしまいます。
- そのため、プログラム側で固定長バッファを管理する必要があります。
- リアルタイムモニタリングに最適
- 実験的機能 (Experimental)
- まだ開発中の機能なので、将来的に仕様が変更される可能性がある
- プロダクション環境では慎重に使用すること
サンプル
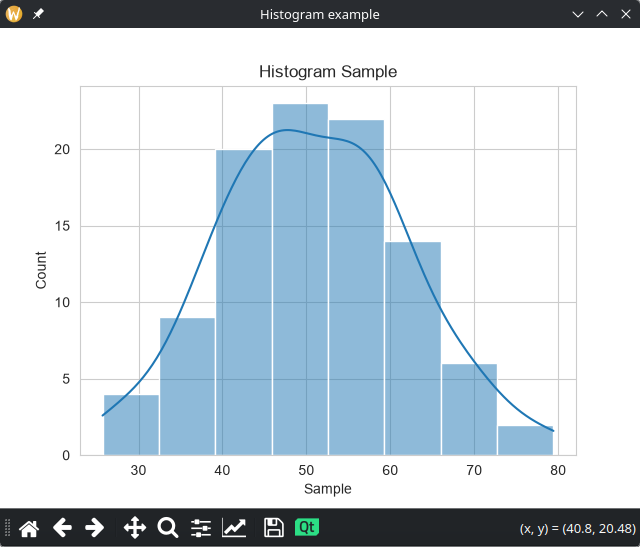
ティックデータから単純な移動平均 MA (n=30) を算出して、株価トレンドと一緒にプロットするサンプルです。チャート作成には PyQtGraph を利用しています。
ツールバーにある ▶(再生ボタン)をクリックすると過去のティックデータ(下記サンプル)を読み込み、100 msec 間隔で新しい点を繋げてプロットします。MA を算出できるようになったら緑線で表示されるようになります。
放っておけばデータの最後までプロットしますが、途中で止める場合は、ツールバーにある ⏹(停止ボタン)をクリックします。
※ このティックデータは、楽天証券のマーケットスピード2 RSS 経由で自作アプリが収集した 2 秒間隔のティックデータです。
上記のサンプルデータを zip のままで、下記サンプルと同じディレクトリ内に保存してサンプルを実行してください。
import sys
from typing import Optional
import numpy as np
import pandas as pd
import pyqtgraph as pg
from PySide6.QtCore import QTimer
from PySide6.QtWidgets import QApplication, QMainWindow, QStyle, QToolBar, QToolButton
from talib import stream
class SampleChart(pg.PlotWidget):
def __init__(self, ma_period: int = 30) -> None:
super().__init__()
self.ma_period = ma_period
# リストで保持(append が高速)
self.data_x: list[float] = []
self.data_y: list[float] = []
self.data_ma: list[float] = []
# streaming APIの状態を保持するためのバッファ
self.y_buffer = np.array([], dtype=float)
self.line: pg.PlotDataItem = self.plot([], [], pen=pg.mkPen(width=0.5))
self.ma: pg.PlotDataItem = self.plot([], [], pen=pg.mkPen((0, 255, 0, 192), width=1))
def add_point(self, x: float, y: float) -> None:
"""新しいデータポイントを追加"""
self.data_x.append(x)
self.data_y.append(y)
# バッファを更新(直近ma_period個のデータのみ保持)
self.y_buffer = np.append(self.y_buffer, y)
if len(self.y_buffer) > self.ma_period:
self.y_buffer = self.y_buffer[-self.ma_period:]
# streaming APIで移動平均を計算
if len(self.y_buffer) >= self.ma_period:
self.data_ma.append(stream.SMA(self.y_buffer, timeperiod=self.ma_period))
# グラフを更新
self.line.setData(self.data_x, self.data_y) # type: ignore
# MA期間に達したらMAラインを表示
if len(self.data_ma) > 0:
ma_start = self.ma_period - 1
self.ma.setData(self.data_x[ma_start:], self.data_ma) # type: ignore
class SampleTaLib(QMainWindow):
def __init__(self) -> None:
super().__init__()
self.file_csv = "sample_data.zip" # ZIP圧縮されたCSVファイルを読み込む
self.df: Optional[pd.DataFrame] = None
self.row: int = 0
self.setWindowTitle("TA-Lib Streaming API Demo")
self.resize(800, 600)
# ツールバーの設定
toolbar = QToolBar()
but_play = QToolButton()
but_play.setIcon(self.style().standardIcon(QStyle.StandardPixmap.SP_MediaPlay))
but_play.clicked.connect(self.on_play_clicked)
toolbar.addWidget(but_play)
but_stop = QToolButton()
but_stop.setIcon(self.style().standardIcon(QStyle.StandardPixmap.SP_MediaStop))
but_stop.clicked.connect(self.on_stop_clicked)
toolbar.addWidget(but_stop)
self.addToolBar(toolbar)
# チャートの設定
self.chart = SampleChart(ma_period=30)
self.setCentralWidget(self.chart)
# タイマーの設定
self.timer = QTimer()
self.timer.setInterval(100)
self.timer.timeout.connect(self.set_new_data)
def on_play_clicked(self) -> None:
"""再生ボタンクリック時の処理"""
try:
# データ未読み込みの場合のみ読み込む
if self.df is None:
self.df = pd.read_csv(self.file_csv)
print(f"CSVファイルを読み込みました: {len(self.df)}行")
# データの検証
if len(self.df.columns) < 2:
print("エラー: CSVファイルには少なくとも2列必要です")
return
if not self.timer.isActive():
self.timer.start()
print("タイマーを開始しました。")
except FileNotFoundError:
print(f"エラー: ファイル '{self.file_csv}' が見つかりません")
except Exception as e:
print(f"エラー: {e}")
def on_stop_clicked(self) -> None:
"""停止ボタンクリック時の処理"""
if self.timer.isActive():
self.timer.stop()
print("タイマーを停止しました。")
def set_new_data(self) -> None:
"""新しいデータをチャートに追加"""
if self.df is None or self.row >= len(self.df):
self.on_stop_clicked()
print("データの最後に到達しました。")
return
try:
x, y = self.df.iloc[self.row, 0], self.df.iloc[self.row, 1]
self.chart.add_point(float(x), float(y))
self.row += 1
except Exception as e:
print(f"データ追加エラー: {e}")
self.on_stop_clicked()
def main() -> None:
app = QApplication(sys.argv)
win = SampleTaLib()
win.show()
sys.exit(app.exec())
if __name__ == "__main__":
main()
CSVファイルを読み込みました: 9691行
タイマーを開始しました。
タイマーを停止しました。
サンプルの実行例
ベンチマーク 追記 [2026-03-12]
Anthropic Claude にベンチマーク用のコードを作ってもらいました。現行のアプリに採用している移動平均を算出するクラスのコア部分を抽出したクラスと、今回の TA-Lib の Streaming API を適用したクラスで比較しました。
import time
from collections import deque
import numpy as np
from talib import stream
# 現在の実装
class MovingAverage:
def __init__(self, window_size: int):
self.window_size = window_size
self.queue = deque()
self.running_sum = 0.0
self.ma = 0.0
self.prev_ma = 0.0
def update(self, value: float) -> float:
if len(self.queue) >= self.window_size:
self.running_sum -= self.queue.popleft()
self.queue.append(value)
self.running_sum += value
self.prev_ma = self.ma
self.ma = self.running_sum / len(self.queue)
return self.ma
# TA-Lib版
class MovingAverageTA:
def __init__(self, window_size: int):
self.window_size = window_size
self.buffer = deque(maxlen=window_size)
self.ma = 0.0
self.prev_ma = 0.0
def update(self, value: float) -> float:
self.buffer.append(value)
if len(self.buffer) >= self.window_size:
self.prev_ma = self.ma
buffer_array = np.array(self.buffer, dtype=float)
self.ma = stream.SMA(buffer_array, timeperiod=self.window_size)
return self.ma
# ベンチマーク
def benchmark(ma_class, iterations=100000):
ma = ma_class(30)
start = time.perf_counter()
for i in range(iterations):
ma.update(float(i))
elapsed = time.perf_counter() - start
return elapsed
# 実行
time_custom = benchmark(MovingAverage)
time_talib = benchmark(MovingAverageTA)
print(f"現在の実装: {time_custom:.4f}秒")
print(f"TA-Lib版: {time_talib:.4f}秒")
print(f"速度比: {time_talib/time_custom:.2f}倍遅い")
デイトレ・アプリを稼働させている Intel N150 搭載の Windows 11 PC 上でのベンチマークの結果は下記のとおりでした。残念ながら Python だけで記述したクラスの方が全然速いという結果になりました。
現在の実装: 0.0263秒
TA-Lib版: 0.5771秒
速度比: 21.98倍遅い
参考サイト
- TA-Lib - Technical Analysis Library
- TA-Lib/ta-lib: TA-Lib (Core C Library)
- TA-Lib/ta-lib-python: Python wrapper for TA-Lib
- TA-Lib · PyPI


 にほんブログ村
にほんブログ村
 #オープンソース
#オープンソース