
Python で強化学習をしようと、いろいろなサイトを調べると CartPole の例をよく見かけます。強化学習をしっかり学んでいる方なら、よく知られた問題なのであらためて調べる必要はないのでしょうが、自分のような初学者にはいまひとつピンときません。
そこで、Gemini に CartPole について説明をしてもらった内容を以下にまとめ直しました。
なお、OpenAI Gym [1] の後継 Gymnasium [2] の利用を前提としているので OpenAI Gym/Gymnasium と記述された部分を Gymnasium だけに直しています。
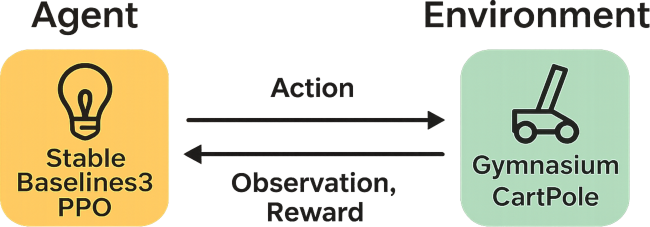
CartPole(カートポール)とは、台車(カート)の上に取り付けられた棒(ポール)を、台車を左右に動かすことで倒れないように制御する、強化学習の分野における古典的な問題であり、またその問題をシミュレーションする Gymnasium の環境名です。
状態(カートの位置・速度、ポールの角度・角速度)を観測し、台車を左右に動かすという 2 つの行動の中から、できるだけ長くポールを立たせておくことを目的とします。
問題の概要
- 台車 (Cart): 左右に動かすことができる台車です。
- 棒 (Pole): 台車の上部に垂直に立てられた棒で、この棒が倒れないように制御します。
- 目的: 棒が倒れないように、台車を左右に動かしてバランスを取ることです。
学習環境
- CartPole は、Gymnasium が提供する強化学習の学習環境に含まれるタスクです。
- AI エージェントが学習を進めるための、定番かつシンプルな環境として広く利用されています。
状態 (Observation)
- 現在の状況は以下の4つの数値で表現されます。
- 台車の位置
- 台車の速度
- ポールの角度
- ポールの角速度
行動 (Action)
- AIエージェントは、以下の2つの行動の中から選択します。
- 台車を左に押す
- 台車を右に押す
報酬 (Reward)
- 各ステップで棒が倒れていなければ、+1 の報酬が与えられます。
- 棒が倒れる、または特定の条件を超えるとエピソードが終了し、報酬が終了します。
終了条件
- 以下のいずれかの条件を満たすと、1つのエピソード(制御タスクの開始から終了まで)が終了します。
- ポールの角度が ±12° より大きくなった場合
- 台車の位置が一定の範囲を超えた場合
- 制御ステップ数が設定された最大値(v0 では 200 ステップ、v1 では 500 ステップ)を超えた場合
Stable-Baselines3 の PPO モデルで学習
Gymnasiom のドキュメント [3] の Basic Usage(以下)のページでは、Your First RL Program に Hello World 的な最初のコードが示されています。
このコードは、倒立振子問題 (CartPole) を扱った出来合いの環境 CartPole-v1 を用いて、ランダムでアクションを生成して、「環境」の動作を確認できるサンプルです。Gymnasium は強化学習エージェントを訓練するための環境を提供するライブラリなので、この程度しかできないのは仕方がないのですが、どうせならエージェントを用意して強化学習をさせてみたくなります。
そこで、同じ OpenAI 由来の Stable-Baselines3 [3] パッケージの PPO を利用して学習させてみました。
下記の OS 環境で動作確認をしています。
通常は Fedora Linux の環境を示しますが、今回はクリーンな状態から Python venv の仮想環境を作って必要なパッケージをインストールして確認したかったので、OS をインストールしたままの状態で運用している AlmaLinux 10 を使用しました。
|
|
AlmaLinux | 10 x86_64_v2 |
| python3 | 3.12.9-2 | |
| python3-devel | ||
| python3-tkinter | ||
| swig | 4.3.0-3 |
Python は本体 (python3) だけでなく、パッケージのビルドに使用する python3-devel と、Matplotlib をインタラクティブモードで使用するために python3-tkinter のパッケージもインストールします。また、swig はパッケージのビルドで必要になります。
開発環境を用意
Python パッケージをインストールする際、一部 C/C++ でコンパイルするものがあるので、次のように開発環境を整えておきます。
$ sudo dnf group install "Development Tools"
Python venv の仮想環境の作成とパッケージのインストール
下記のように例えば rl_cartpole というディレクトリを作成して、その中で venv の仮想環境を作成します。多くの場合、pip のバージョンが古くなっているので、気になる場合はあらかじめアップデートします。
$ mkdir rl_cartpole $ cd rl_cartpole $ python -m venv venv $ source venv/bin/activate (venv) $ pip install --upgrade pip
以下のように gymnasium と stable-baseline3 パッケージをインストールします。必要な関連パッケージもインストールされます。
(venv) $ pip install gymnasium[box2d] stable-baselines3[extra]
強化学習用サンプル
Gymnasium には出来合いの環境がいくつも用意されています。一覧は下記のとおりです。
import gymnasium as gym gym.pprint_registry()
===== classic_control =====
Acrobot-v1 CartPole-v0 CartPole-v1
MountainCar-v0 MountainCarContinuous-v0 Pendulum-v1
===== phys2d =====
phys2d/CartPole-v0 phys2d/CartPole-v1 phys2d/Pendulum-v0
===== box2d =====
BipedalWalker-v3 BipedalWalkerHardcore-v3 CarRacing-v3
LunarLander-v3 LunarLanderContinuous-v3
===== toy_text =====
Blackjack-v1 CliffWalking-v1 CliffWalkingSlippery-v1
FrozenLake-v1 FrozenLake8x8-v1 Taxi-v3
===== tabular =====
tabular/Blackjack-v0 tabular/CliffWalking-v0
===== None =====
Ant-v2 Ant-v3 GymV21Environment-v0
GymV26Environment-v0 HalfCheetah-v2 HalfCheetah-v3
Hopper-v2 Hopper-v3 Humanoid-v2
Humanoid-v3 HumanoidStandup-v2 InvertedDoublePendulum-v2
InvertedPendulum-v2 Pusher-v2 Reacher-v2
Swimmer-v2 Swimmer-v3 Walker2d-v2
Walker2d-v3
===== mujoco =====
Ant-v4 Ant-v5 HalfCheetah-v4
HalfCheetah-v5 Hopper-v4 Hopper-v5
Humanoid-v4 Humanoid-v5 HumanoidStandup-v4
HumanoidStandup-v5 InvertedDoublePendulum-v4 InvertedDoublePendulum-v5
InvertedPendulum-v4 InvertedPendulum-v5 Pusher-v4
Pusher-v5 Reacher-v4 Reacher-v5
Swimmer-v4 Swimmer-v5 Walker2d-v4
Walker2d-v5
今回は CartPole-v1 の学習環境を試します。gym.make で以下のように CartPole-v1 を指定することで Gymnasium の仕様に準拠した CartPole-v1 の学習環境 env を生成できます。
env = gym.make("CartPole-v1")
先に触れた Gymnasiom のドキュメント [3] の Basic Usage のページ、Your First RL Programで示されているコードをベースにして、Stable-Baselines3 パッケージの PPO を利用して学習できるようにしたのが下記のコードです。
PPO では、多層パーセプトロン (MLP) ベースの方策と価値関数を使う MlpPolicy を指定しています。
このコードを適当なファイル名(例: cartpole_rl.py)で保存して学習を実行します。
import os
import gymnasium as gym
from stable_baselines3 import PPO
from stable_baselines3.common.monitor import Monitor
if __name__ == "__main__":
# ログフォルダの準備
dir_log = "./logs/"
os.makedirs(dir_log, exist_ok=True)
# 学習環境の準備
env = gym.make("CartPole-v1", render_mode="human")
env = Monitor(env, dir_log) # Monitorの利用
# モデルの準備
model = PPO("MlpPolicy", env, verbose=True)
# 学習の実行
model.learn(total_timesteps=50000)
# 推論の実行
obs, info = env.reset()
print(f"Starting observation: {obs}")
episode_over = False
total_reward = 0
while not episode_over:
action, _ = model.predict(obs, deterministic=True)
obs, reward, terminated, truncated, info = env.step(action)
total_reward += reward
episode_over = terminated or truncated
print(f"Episode finished! Total reward: {total_reward}")
env.close()
(venv) $ python cartpole_rl.py
CartPole の棒が揺れながらバランスを取る様子がウィンドウに表示され、学習後に推論が実行されます。

Using cpu device Wrapping the env in a DummyVecEnv. /home/bitwalk/MyProjects/rl_cartpole/venv/lib64/python3.12/site-packages/pygame/pkgdata.py:25: UserWarning: pkg_resources is deprecated as an API. See https://setuptools.pypa.io/en/latest/pkg_resources.html. The pkg_resources package is slated for removal as early as 2025-11-30. Refrain from using this package or pin to Setuptools<81. from pkg_resources import resource_stream, resource_exists --------------------------------- | rollout/ | | | ep_len_mean | 22.1 | | ep_rew_mean | 22.1 | | time/ | | | fps | 47 | | iterations | 1 | | time_elapsed | 43 | | total_timesteps | 2048 | --------------------------------- ----------------------------------------- | rollout/ | | | ep_len_mean | 29 | | ep_rew_mean | 29 | | time/ | | | fps | 46 | | iterations | 2 | | time_elapsed | 87 | | total_timesteps | 4096 | | train/ | | | approx_kl | 0.008222323 | | clip_fraction | 0.0791 | | clip_range | 0.2 | | entropy_loss | -0.687 | | explained_variance | -0.00142 | | learning_rate | 0.0003 | | loss | 6.95 | | n_updates | 10 | | policy_gradient_loss | -0.0101 | | value_loss | 54.3 | ----------------------------------------- ... (途中省略) ... ----------------------------------------- | rollout/ | | | ep_len_mean | 398 | | ep_rew_mean | 398 | | time/ | | | fps | 47 | | iterations | 25 | | time_elapsed | 1079 | | total_timesteps | 51200 | | train/ | | | approx_kl | 0.004092879 | | clip_fraction | 0.043 | | clip_range | 0.2 | | entropy_loss | -0.489 | | explained_variance | 0.0157 | | learning_rate | 0.0003 | | loss | 0.0149 | | n_updates | 240 | | policy_gradient_loss | -0.00138 | | value_loss | 0.021 | ----------------------------------------- Starting observation: [ 0.0244522 0.03066805 0.03330757 -0.04372405] Episode finished! Total reward: 500.0
出力される学習に関連する情報について、Gemini に教えてもらった内容を以下にまとめました。
- rollout
- データ収集・エピソード結果
- このセクションは、エージェントが環境と相互作用してデータを収集した結果を示します。
- ep_len_mean
- 平均エピソード長 (Episode Length Mean)
- 直近のエピソードのステップ数の平均値です。デイトレ環境の場合、1日のティック数、またはエピソードが終了するまでの平均時間ステップを示します。
- ep_rew_mean
- 平均エピソード報酬 (Episode Reward Mean)
- 直近のエピソードでエージェントが得た累積報酬(総利益)の平均値です。この値の増加が、学習が順調に進んでいるかどうかの最も重要な指標となります。
- ep_len_mean
- time
- 時間・実行速度に関する指標
- このセクションは、学習プロセス自体の効率と進捗を示します。
- fps
- フレーム毎秒 (Frames Per Second)
- 1 秒あたりに処理されたタイムステップの数。学習の処理速度を示し、高いほど効率的です。
- iterations
- イテレーション数
- PPO の更新サイクルが何回実行されたかを示す回数です。通常、total_timesteps が n_steps * n_envs(データバッファサイズ)に達するごとに 1 回インクリメントされます。
- time_elapsed
- 経過時間 (秒)
- 学習開始からの合計経過時間です。
- total_timesteps
- 総タイムステップ数
- 学習開始から現在までに環境と相互作用した合計のステップ数です。
- fps
- train
- 学習の質に関する指標
- このセクションの指標は、モデル(ポリシーと価値関数)がどれだけうまくデータに適合し、ポリシーの更新が適切に行われているかを示します。
- approx_kl
- 近似 KL ダイバージェンス (Approximate KL Divergence)
- 更新後の新しいポリシーと、更新前の古いポリシーとの間の距離を示します。PPO は、ポリシーが急激に変化するのを防ぐため、この値が大きくなりすぎないように制御します。
- clip_fraction
- クリップされた割合 (Clipped Fraction)
- 勾配更新時に、PPO のクリッピング機構によって損失が制限されたサンプルデータの割合です。この値が高すぎると、クリッピングが強すぎて学習が進まない可能性があります。
- clip_range
- クリップ範囲
- PPO のハイパーパラメータであり、ポリシー更新時の比率(rt(θ))を制限する範囲(例:[1−ϵ, 1+ϵ] の ϵ)。ここでは ϵ=0.2 と設定されています。
- entropy_loss
- エントロピー損失
- エージェントの行動のランダム性(探索の度合い)に関する損失項。値が負で、絶対値が大きいほど、ポリシーの行動がランダムで多様であることを示します。徐々に 0 に近づくことが期待されます。
- explained_variance
- 説明された分散
- 価値関数 (Value Function) が、実際の累積報酬(リターン)をどれだけうまく予測できているかを示す指標。1 に近いほど、予測精度が高いことを示します。負の値は、予測が平均より悪いことを示し、モデルの不安定さを示唆します。
- learning_rate
- 学習率
- ニューラルネットワークの重みを更新する際のステップサイズです。PPO では、学習の進行とともに線形に減衰(スケジューリング)されることが一般的です。
- loss
- 全体の損失関数(ポリシー損失 + 価値関数損失 + エントロピー損失など)の合計。
- この値が小さくなるほど学習は進んでいると見なされますが、個別の損失に比べて解釈は難しいです。
- n_updates
- これまでの総更新回数。
- Iteration 数と n_epochs (1つの Iteration 内でモデルを更新する回数) の積です。
- policy_gradient_loss
- ポリシー勾配損失
- PPO の主要な損失関数で、ポリシー(行動戦略)の更新に使用されます。負の値を示し、負の絶対値が大きいほど、ポリシーが更新によって報酬を増加させる方向に強く引っ張られていることを意味します。
- value_loss
- 価値損失
- 価値関数(状態の価値を予測するネットワーク)の更新に使用される損失です。この値が低いほど、価値関数が正確に状態の価値を予測できていることを示します。
- approx_kl
学習曲線の確認
PPO を利用して学習をできるようにしたコード(cartpole_rl.py)では、gym.make で生成した環境 env を Monitor に通しています。この Monitor は、Stable-Baselines3 パッケージが提供する Gymnasium 環境向けのモニターラッパーで、エピソード報酬、長さ、時間、その他のデータを把握するために使用します。
このサンプルでは、dir_log (= "./logs/") 内にログを保存するように設定しています。
# 学習環境の準備
env = gym.make("CartPole-v1", render_mode="human")
env = Monitor(env, dir_log) # Monitorの利用
学習を実行した後、dir_log (= "./logs/") 内を確認すると monitor.csv というファイルがあり、最初の行がコメント行になっていて、以下 r(エピソード報酬)、l(エピソードの長さ)、t(時間)が記録されています。
(venv) $ ls logs monitor.csv (venv) $ cat logs/monitor.csv #{"t_start": 1759387094.2588797, "env_id": "CartPole-v1"} r,l,t 12.0,12,8.555453 18.0,18,8.94126 18.0,18,9.327632 ... (以下省略)
報酬トレンド
CartPole-v1 では 500 ステップが上限なので、最大ステップまで棒 (Pole) が倒れなければ報酬は +500 になり、これが最大です。すなわち、報酬を最大化することが、できるだけ長くポールを立たせておくという目的と一致しています。
報酬がどのように増えるかをエピソード順にプロットすることで、学習曲線を確認できます。
import os
import pandas as pd
import matplotlib.pyplot as plt
if __name__ == "__main__":
# monitor.csv の読み込み
dir_log = "./logs"
name_log = "monitor.csv"
# 最初の行の読み込みを除外
df = pd.read_csv(os.path.join(dir_log, name_log), skiprows=[0])
# 報酬のプロット
plt.plot(df["r"])
plt.xlabel("episode")
plt.ylabel("reward")
plt.grid()
plt.tight_layout()
plt.show()
(venv) $ python plot_monitor_reward.py
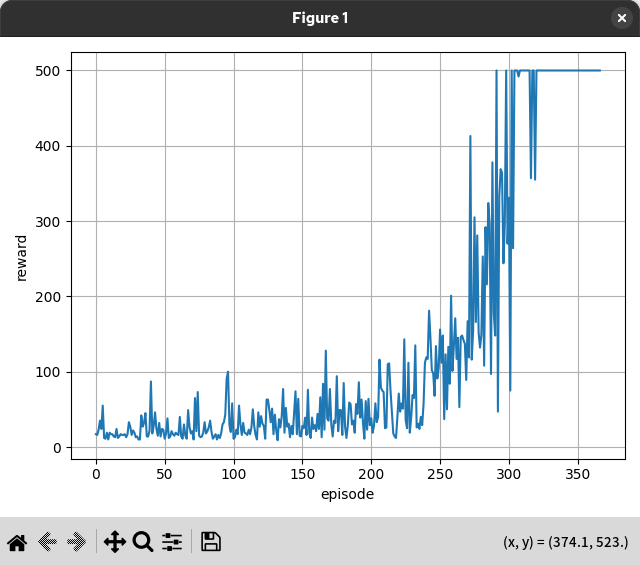
この例では、エピソードが 350 回に近づくと報酬が 500 になっています。350 回程度のエピソード(学習回数)で、モデルは報酬を最大化できた、すなわち、棒を倒さないコツを学習できたと言えるでしょう。
なお、エピソードの回数とエピソードの長さの積の累積が、cartpole_rl.py における下記の total_timesteps を超えない範囲で学習が行われますので、もう少し確認したければ数値を大きくする必要があります。
# 学習の実行
model.learn(total_timesteps=50000)
まとめ
強化学習を利用したい、というニーズあって、そのために Gymnasium であれこれ環境を作っています。最近、少し行き詰まってきたと感じたので、かき集めた知識を整理するためにも一旦立ち止まって、CartPole-v1 のような出来合いの環境を試してみました。
書いてまとめることによって自分の理解の整理ができて、行き詰まり感も解消できたことは良かったのですが、興味がある部分を中心にまとめてしまったきらいがあります。おいおい足りない部分を書き足します。
参考サイト
- openai/gym: A toolkit for developing and comparing reinforcement learning algorithms.
- Farama-Foundation/Gymnasium (formerly Gym)
- Gymnasium Documentation
- DLR-RM/stable-baselines3: PyTorch version of Stable Baselines
- Stable-Baselines3 Docs - Reliable Reinforcement Learning Implementations
- Monitor Wrapper — Stable Baselines3 documentation
- Stable Baselines 3 入門 (1) - 強化学習アルゴリズム実装セット|npaka
- Stable Baselines 3 入門 (2) - Monitor|npaka
にほんブログ村

#オープンソース

0 件のコメント:
コメントを投稿