
このところ、利用するプログラミング言語は、すっかり Python だけになってしまいました。しかし、Python の入門書で網羅的に勉強してこなかったツケを感じています。あるデータの集計方法について、生成 AI に教えてもらった内容があまりに素晴らしくて悔しい思いをしました。いまだに Python の標準ライブラリを使いこなせないのは恥ずかしいかぎりです。
生成 AI に教えてもらってその場の対応だけで満足してしまうと、後日、同じような場面で同じような質問を生成 AI に尋ねて、もっと悔しい思いをするのは明白なので、忘れないように事象を単純化して備忘録にしました。
- 完全実施要因計画 (Full Factorial Design) の実験データを各実験因子毎に集計したい。
- ただし、実験因子候補のパラメータは多数あり、実用上、実験因子にするのはその一部で、実験の度に実験因子や実験水準を変更。
- 実験因子をリストで指定するだけで、実験水準を調べて実験因子の水準の組み合わせ毎に集計したい。
下記の OS 環境で動作確認をしています。

|
Fedora Linux 44 Workstation Edition x86_64 |
|
| Python | 3.14.4 | |
| jupyterlab | 4.5.7 | |
単純化した問題
問題を単純化して Jupyter Lab 上で集計する例をまとめました。
ライブラリのインポート
まず、使用するライブラリをまとめてインポートします。
import operator from functools import reduce from itertools import product import pandas as pd
実験データの読み込み
実験データ(サンプル)は、下記からダウンロードできます。
| sample_doe.zip |
# 実験結果を読み込む file = "sample_doe.zip" df = pd.read_csv(file) df
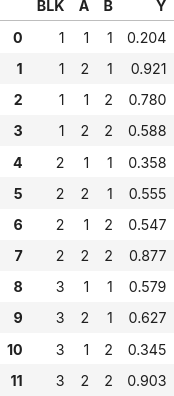
実験因子は A と B で、それぞれ2水準です。Y は結果(特性値)です。
BLK は実験の実施単位(ブロック因子)です。仮に日付と見なせば、3日間、完全実施要因計画 (Full Factorial Design) の(ランダマイズ無しに)実験を繰り返したことになります。
実験因子の指定と実験水準の確認
実験因子の指定は仕方がないとしても、実験水準の確認はプログラムで調べます。
# 実験因子 list_factor = ["A", "B"] # 各実験因子毎の実験水準 levels = [sorted(list(df[factor].unique())) for factor in list_factor] levels
[[np.int64(1), np.int64(2)], [np.int64(1), np.int64(2)]]
サンプルを単純化しているので触れませんが、現実に使っている実験因子+結果のデータは、実験因子に指定していないパラメータ列も含んでいるので、水準が複数あるパラメータを実験因子として抽出するようにしています。
集計処理
集計ループの部分が、今回の目的になります。itertools.product を利用すると各リストの要素の組み合わせをタプルで取得できます。
# 各因子、各実験水準毎に平均値を集計
rows = []
for combo in product(*levels):
condition = dict(zip(list_factor, combo))
mask = reduce(operator.and_, (df[k] == v for k, v in condition.items()))
avg = df[mask]["Y"].mean()
row = {**condition, "avg": avg}
rows.append(row)
rows
[{'A': np.int64(1), 'B': np.int64(1), 'avg': np.float64(0.38033333333333336)},
{'A': np.int64(1), 'B': np.int64(2), 'avg': np.float64(0.5573333333333333)},
{'A': np.int64(2), 'B': np.int64(1), 'avg': np.float64(0.701)},
{'A': np.int64(2), 'B': np.int64(2), 'avg': np.float64(0.7893333333333333)}]
ループを抜けた後ですが、気になる変数の内容を確認します。
combo
(np.int64(2), np.int64(2))
condition
{'A': np.int64(2), 'B': np.int64(2)}
mask
0 False 1 False 2 False 3 True 4 False 5 False 6 False 7 True 8 False 9 False 10 False 11 True dtype: bool
集計結果をデータフレーム化
最後に、rows をデータフレームにします。
df_summary = pd.DataFrame(rows)
# 行、列が長い時に省略されないように一時的に最大設定を解除
with pd.option_context('display.max_rows', None, 'display.max_columns', None):
print(df_summary)
A B avg 0 1 1 0.380333 1 1 2 0.557333 2 2 1 0.701000 3 2 2 0.789333
まとめ
今回使用した product は、Python のドキュメント [2] によると、「デカルト積、ネストしたforループと等価」とあります。Python のコーディングではいつもお世話になっているサイト note.nkmk.me にも、profuct についてサンプル付きで紹介されています [4]。
しかし、問題意識が無い状態で読んでも心に響きません。心に響かなければ記憶にも残らないので、いざ必要な場面に遭遇しても結びつかず、泥臭いやり方でコーディングをする愚を冒します。
今回は実験因子が A と B の2つだけなので、product のありがたみが薄いのですが、因子数が増えても同じループで処理できるので、とても助かります。あやうく、因子数に応じた多重ループを用意してしまうところでした。
生成 AI に尋ねると、自分が知らなかったこと、記憶にあるけど活用できないことをぐいぐい活用していて驚くことがあります。これは、単に自分がノウハウを持っていないことに他ならないので、コーディングが面倒だと感じたら、迷わず生成 AI に尋ねる習慣がついてしまいました。
参考サイト
- functools --- 高階関数と呼び出し可能オブジェクトの操作 — Python ドキュメント
- itertools --- 効率的なループ用のイテレータ生成関数群 — Python ドキュメント
- operator --- 関数形式の標準演算子 — Python ドキュメント
- Pythonで複数のリストの直積(デカルト積)を生成するitertools.product | note.nkmk.me
にほんブログ村

#オープンソース
