
日経平均株価は、日本経済新聞社が算出・公表している日本の株式市場の代表的な株価指数の一つです。東京証券取引所プライム市場に上場している約 2,000 銘柄の株式のうち、取引が活発で流動性が高い 225 銘柄を、日本経済新聞社が選定し算出します。構成銘柄は 4 月と 10 月の年 2 回、上限各 3 銘柄の定期入れ替えが実施されています。
Wikipedia より引用、編集
日経平均株価の構成銘柄を Python で取得しようと Jupyter Lab 上で、参考サイト [1] に従って試したところ、以下のようにエラーが出て取得できませんでした。
dfs = pd.read_html("https://indexes.nikkei.co.jp/nkave/index/component")
--------------------------------------------------------------------------- HTTPError Traceback (most recent call last) ... (途中省略) ... 612 def http_error_default(self, req, fp, code, msg, hdrs): --> 613 raise HTTPError(req.full_url, code, msg, hdrs, fp) HTTPError: HTTP Error 403: Forbidden
ところが、端末エミュレータ上で同じ URL を wget コマンドで同じサイトを取得してみたところ、難なく出来てしまいました。
上記 Pandas で読み込むやり方でも、何か工夫をすれば読み込めるのかもしれませんが、とりあえず Python から wget コマンドを実行して、読み込みたいサイトを一旦ローカルファイルに保存してから、そのファイルを Pandas で読み込むことで、やりたかったことをできるようになったので、備忘録にしました。
下記の OS 環境で動作確認をしています。

|
Fedora Linux Workstation | 42 x86_64 |
| Python | 3.13.7 | |
| beautifulsoup4 | 4.14.2 | |
| html5lib | 1.1 | |
| JupyterLab | 4.4.9 | |
| lxml | 6.0.2 | |
| pandas | 2.3.3 | |
| wget2 | 2.2.0-5 (rpm) |
サンプル
以下、Jupyter Lab 上で実行することを想定しています。
最初に利用するライブラリをまとめてインポートします。
import os import subprocess import pandas as pd
外部コマンドを実行する関数です。ピッタリな用途の関数が公開されていたので、そのまま流用させていただきました。
# Reference:
# https://brightdata.jp/blog/各種ご利用方法/wget-with-python
def execute_command(command):
"""
Execute a CLI command and return the output and error messages.
Parameters:
- command (str): The CLI command to execute.
Returns:
- output (str): The output generated by the command.
- error (str): The error message generated by the command, if any.
"""
try:
# execute the command and capture the output and error messages
process = subprocess.Popen(
command, shell=True, stdout=subprocess.PIPE, stderr=subprocess.PIPE
)
output, error = process.communicate()
output = output.decode("utf-8")
error = error.decode("utf-8")
# return the output and error messages
return output, error
except Exception as e:
# if an exception occurs, return the exception message as an error
return None, str(e)
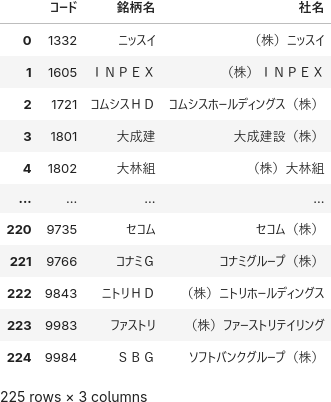
日経平均株価の構成銘柄をデータフレームで取得する処理です。
# wget コマンドで対象サイトをダウンロード
file = "component"
# ファイルが存在していれば削除
if os.path.exists(file):
os.remove(file)
output, error = execute_command(f"wget https://indexes.nikkei.co.jp/nkave/index/{file}")
# 保存された HTML ファイルを Pandas で読み込む
dfs = pd.read_html(file)
# 複数のデータフレームを結合して、コード列でソート
df = pd.concat(dfs).sort_values("コード", ignore_index=True)
df
参考サイト
にほんブログ村

#オープンソース

0 件のコメント:
コメントを投稿