Pandas は、プログラミング言語 Python において、データ解析を支援する機能を提供するライブラリです。特に、数表および時系列データを操作するためのデータ構造と演算を提供します。Pandas は BSD ライセンスのもとで提供されています。Pandas の 開発により、R 言語における DataFrame が扱える「ベクトル処理」の操作性と同等な機能が導入されました。
Wikipedia より引用、編集
空の Pandas のデータフレームを用意して、一行ずつデータを追加していきたい場面になると、いつも、あちこちネットで調べて、その場しのぎのやり方で対応してしまっています。
その場しのぎのやり方は、毎回まちまちなので、自分にとってベストなやり方を探索するために、今回たどり着いたやり方を備忘録にしました。もっとよいやり方が見つかれば、あらためて備忘録にしていきたいと考えています。
下記の OS 環境で動作確認をしています。

|
Fedora Linux 41 Workstation | x86_64 |
| Python | 3.13.1 | |
| jupyterlab | 4.3.5 | |
| numpy | 2,2,2 | |
| pandas | 2.2.3 |
以下の作業は JupyterLab 上でおこなっています。
最初に必要なライブラリをインポートします。
import numpy as np import pandas as pd
列名になる要素名(キー)と空の要素からなる辞書型変数を用意し、Pandas のクラスメソッド from_dict を使って、列名だけ定義された空のデータフレームを作成します。さらに、データフレーム全体を object 型にキャストしておきかえておきます。追加するデータが数値だけであればキャストする必要はありません。
dict_columns = {
'A': [],
'B': [],
'C': [],
}
df = pd.DataFrame.from_dict(dict_columns)
df = df.astype(object)
df

一行追加します。
r = len(df) df.at[r, 'A'] = 1. df.at[r, 'B'] = 2 df.at[r, 'C'] = '' df

確認用にもう一行追加します。
r = len(df) df.at[r, 'A'] = 3 df.at[r, 'B'] = None df.at[r, 'C'] = np.nan df
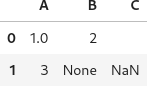
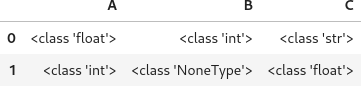
各セルの型を確認すると以下のようになっています。
df.map(type)
参考サイト
- pandas.DataFrame.from_dict — pandas documentation
- pandas.DataFrame.astype — pandas documentation
- pandas.DataFrame.map — pandas documentation
にほんブログ村

#オープンソース

0 件のコメント:
コメントを投稿