GhostBSD は FreeBSD ベースの Unix ライクな OS で、 デフォルトのデスクトップ環境には MATE が採用されており、 コミュニティベースの Xfce 版も利用できます。インストールが簡単で、すぐに使えて、使いやすいことを目指しています。プロジェクトの目標は、セキュリティ、プライバシー、安定性、ユーザビリティ、オープン性、自由を兼ね備え、無償であることです。
UNIX 本流と言える BSD 由来の FreeBSD は、UNIX 大好きの自分にとって憧れの OS でした。しかし、Linux の圧倒的な情報量の多さ、便利さ、インストールの簡単さに惹きつけられてしまって、いまだ FreeBSD に正面から取り組んでいません。ひさしぶりに GhostBSD を仮想環境にインストールして、いまどきの BSD に触れてみました。
インストール
インストール用 iso イメージ
インストールに使用した iso イメージは下記の通りです。
| GhostBSD 24.01.1 | 64-bit, amd64 | GhostBSD-24.01.1.iso | 入手先 |
システム要件
- 2 GHz の 2コア Intel/ARM 64-bit プロセッサ
- 4 GB RAM
- VGA 互換、1024x768 解像度のディスプレイ
- ネットワークカード
- 15 GB のストレージ容量
- インストールメディア用の CD/DVD ドライブあるいは USB ポート
RAM が 4GB 以上でないとインストールがうまくできないと、ダウンロードサイトに注記されています。
また、ネットワークカードが必要だと記載されていますが、WiFi には対応しているのか気になるところです。もちろん、仮想環境にインストールする際は有線ネットワークを前庭としているので問題ありません。
仮想環境へインストール
GNOME Boxes の仮想環境にインストールした例を紹介します。
iso ファイルを読み込むと、下のような起動画面が表示されます。
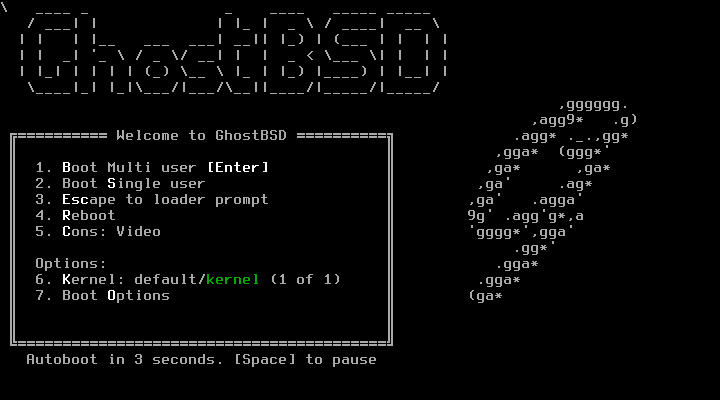
Enter キーをタイプして Boot multi user を選択して次へ進むと、X(ウィンドウシステム)の自動起動に失敗したというメッセージが表示されて、デスクトップのオプションの選択が求められます。
※ これはもしかすると、GNOME Boxes を使用していることが原因かもしれません。
とりあえず選択されている一番上の Intel のまま Enter キーをタイプします。
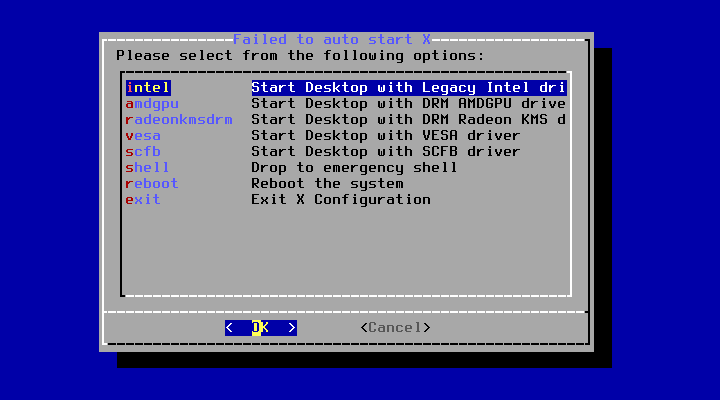
すると無事に GhostBSD のデスクトップ画面が表示されます。

デスクトップ画面の左側にある Install GhostBSD のアイコンをダブルクリックして、インストーラを起動します。
インストーラの最初の画面で、言語(ロケール)の選択をします。日本語を選択しても、インストーラの表示言語は英語のままで変わりません。
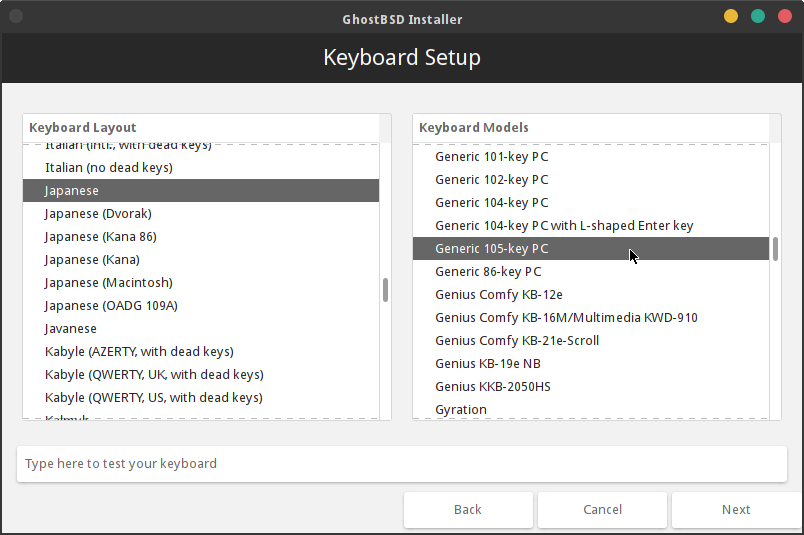
次にキーボードのレイアウトを選択します。レイアウトに Japanese、モデル(?)に(とりあえず)Generic 105-key PC を選びました。
タイムゾーンを選択します。Continent(大陸)は Asia、City は Tokyo を選びました。
インストールタイプは Full disk configuration のままです。
インストール先のストレージを選択します。
ZFS は、かつての Sun Microsystems 社が開発して Solaris OS で採用されていたファイルシステムで、現在は Oracle 社が権利を所有しています。おそらく GhostBSD が採用しているファイルシステムはオープンソース版の OpenZFS の方だろうと思われます。[要確認]
ブートオプションは変更せずに次へ進みます。
ユーザーアカウントを設定します。ここで設定するユーザーは sudo でスーパーユーザーになれるアカウントのようです。この画面で Install ボタンをクリックするとインストールが始まります。
インストールにしばらく時間がかかります。画面下にインストールの進捗が表示されます。
インストールが完了すると、このままライブ OS を試用し続ける (Continue) か、再起動 (Reestart) するか選択するダイアログが表示されます。ここでは Restart ボタンをクリックして再起動します。
再起動後、ログイン画面が表示されます。インストール直後の最初の起動では下記のように真っ黒の背景でしたが、2回目以降はデスクトップ画面と同じ背景が表示されました。最初の起動でなにかがうまく起動しなかっただけなのかもしれません。
ログインするとデスクトップ画面が表示されます。

パッケージの更新
インストール後、はじめてログインしてしばらくすると、下記のように、更新するパッケージがある (Update Available) というメッセージが表示されます。

パッケージの更新は、Update Manager という GUI アプリが用意されています。
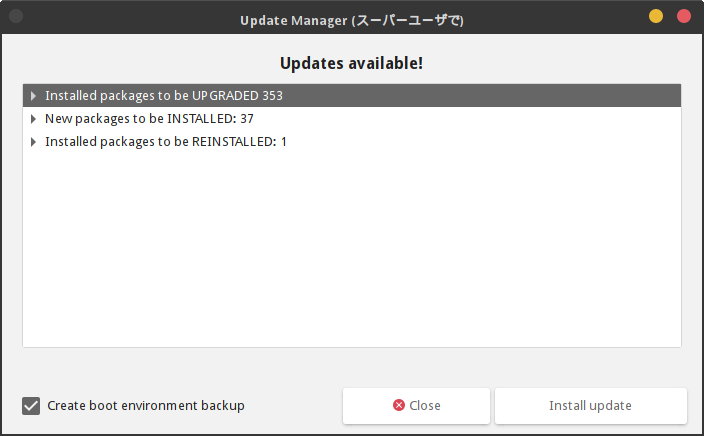
しかし、ここでは敢えて端末エミュレータでコマンド入力でパッケージを更新します。
あいにく、端末エミュレータを含むデスクトップ環境 MATE などの大きな更新で、端末エミュレーターなどが更新中に消えてしまい、なにも操作ができなくなってしまいました😭。こんなことってあるんですね。
仮想環境なので GhostBSD のインストールをし直し、ここは素直に上記 Update Manager を使って(Install update をクリックして)更新をしました。
更新中は以下のように進捗が表示されます。
更新が終わるまで気長に待ちます。更新が終わると再起動をするかどうか尋ねるダイアログが表示されますので、Restart Now ボタンをクリックして再起動します。
MATE のバージョン
パッケージの更新後、MATE が最新のバージョンになりました。

キーボードのレイアウト
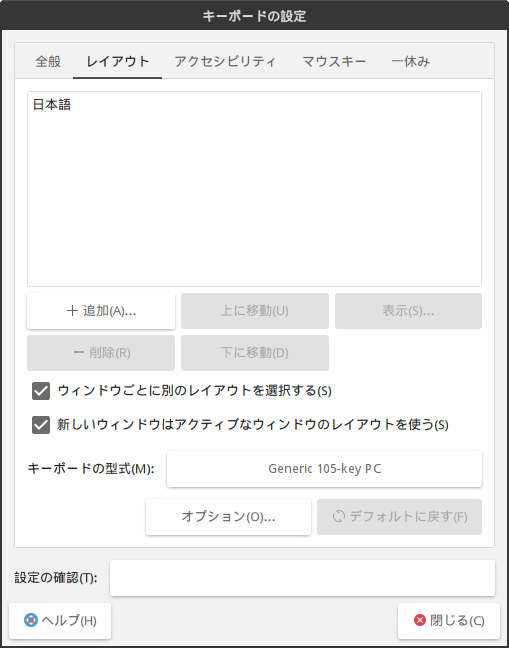
インストール時にキーボードのレイアウトの設定をしたはずなのに、デスクトップ環境 MATE には反映されていませんでした。なお、キーボードの形式(モデル)は残っていました。
画面上部のメニューから「システム」→「設定」→「ハードウェア」→「キーボード」を選んで、「レイアウト」のタブで「日本語」に設定しておきます。
日本語用インプットメソッドの設定
画面上部のメニューから「アプリケーション」→「システムツール」→「MATE 端末」を選んで、端末エミュレータを起動します。
pkg コマンドで ibus の文字列を含むパッケージを探します。検索だけであればスーパーユーザーになる必要はありませんが、一応 sudo コマンドでスーパーユーザーで実行しました。
Welcome to fish, the friendly interactive shell Type help for instructions on how to use fish bitwalk@bitwalk-ghostbsd ~> sudo pkg search ibus あなたはシステム管理者から通常の講習を受けたはずです。 これは通常、以下の3点に要約されます: #1) 他人のプライバシーを尊重すること。 #2) タイプする前に考えること。 #3) 大いなる力には大いなる責任が伴うこと。 セキュリティー上の理由で、あなたがタイプしたパスワードは表示しません。 パスワード: ibus-1.5.29_1 Intelligent Input Bus for Unix-like systems ibus-kmfl-1.0.3_7 KMFL IMEngine for IBus framework ibus-m17n-1.4.28 m17n IM engine for IBus framework ibus-table-1.17.4_1 Table-based input method framework for IBus ibus-typing-booster-2.25.3 Faster typing by context sensitive completion ibus-uniemoji-0.6.0.16 Input method for entering unicode symbols and emoji by name ja-ibus-anthy-1.5.11 Anthy engine for IBus ja-ibus-mozc-2.23.2815.102.01_17 Mozc engine for IBus ja-ibus-skk-1.4.3_2 Japanese SKK input engine for IBus ko-ibus-hangul-1.5.1_2 Hangul input engine for IBus libusbmuxd-2.0.2_1 Communication interface library for usbmuxd libusipp-2.25 Unix socket interface for C++ raw IP/IP6/UDP/TCP, layer 2 framework libusrsctp-0.9.5.0 Portable SCTP userland stack linux_libusb-13.1.0 Linux-compatibility LibUSB py39-libusb1-3.1.0 Pure-python wrapper for libusb-1.0 rubygem-omnibus-9.0.24 Framework for building self-installing, full-stack software builds scribus-1.6.1_1 Comprehensive desktop publishing program scribus-devel-1.5.8_25 Comprehensive desktop publishing program (development version) usbrh-libusb-0.05_1 Yet another reads temperatures and humidity from a Strawberry Linux USB-RH zh-ibus-array-0.2.2.20230502 Array 30 input method for IBus zh-ibus-cangjie-2.4 IBus engine for users of the Cangjie and Quick zh-ibus-chewing-1.5.1_1 Chewing engine for IBus zh-ibus-libpinyin-1.15.4 Intelligent Pinyin engine based on libpinyin for IBus zh-ibus-pinyin-1.5.0_10 PinYin engine for IBus zh-ibus-rime-1.5.0_1 IBus engine for Rime users zh-ibus-table-chinese-1.8.12 Chinese input tables for IBus bitwalk@bitwalk-ghostbsd ~>
ibus で Mozc を利用できるので、これをインストールします。
bitwalk@bitwalk-ghostbsd ~> sudo pkg install ja-ibus-mozc Updating GhostBSD repository catalogue... GhostBSD repository is up to date. All repositories are up to date. The following 9 package(s) will be affected (of 0 checked): New packages to be INSTALLED: ibus: 1.5.29_1 ja-ibus-mozc: 2.23.2815.102.01_17 ja-mozc-server: 2.23.2815.102.01_17 ja-mozc-tool: 2.23.2815.102.01_17 ja-tegaki-zinnia-japanese: 0.3 ja-zinnia: 0.06_2 jsoncpp: 1.9.5 protobuf: 24.4,1 qt5-buildtools: 5.15.13p142 Number of packages to be installed: 9 The process will require 148 MiB more space. 41 MiB to be downloaded. Proceed with this action? [y/N]: y [1/9] Fetching ja-ibus-mozc-2.23.2815.102.01_17.pkg: 100% 259 KiB 264.8kB/s 00:01 ... ... [9/9] Fetching ja-mozc-tool-2.23.2815.102.01_17.pkg: 100% 851 KiB 871.6kB/s 00:01 Checking integrity... done (0 conflicting) [1/9] Installing jsoncpp-1.9.5... [1/9] Extracting jsoncpp-1.9.5: 100% ... ... [9/9] Installing ja-ibus-mozc-2.23.2815.102.01_17... [9/9] Extracting ja-ibus-mozc-2.23.2815.102.01_17: 100% ==> Running trigger: gtk-update-icon-cache.ucl Generating GTK icon cache for /usr/local/share/icons/hicolor ==> Running trigger: glib-schemas.ucl Compiling glib schemas ==> Running trigger: desktop-file-utils.ucl Building cache database of MIME types ===== Message from ibus-1.5.29_1: -- ibus installation finished. To use ibus, please do the following: If you are using bash, please add following lines to your $HOME/.bashrc: export XIM=ibus export GTK_IM_MODULE=ibus export QT_IM_MODULE=ibus export XMODIFIERS=@im=ibus export XIM_PROGRAM="ibus-daemon" export XIM_ARGS="--daemonize --xim" If you are using tcsh, please add following lines to your $HOME/.cshrc: setenv XIM ibus setenv GTK_IM_MODULE ibus setenv QT_IM_MODULE ibus setenv XMODIFIERS @im=ibus setenv XIM_PROGRAM ibus-daemon setenv XIM_ARGS "--daemonize --xim" If you are using KDE4, you may create a shell script in $HOME/.kde4/env ($HOME/.config/plasma-workspace/env for Plasma) and add following lines: #!/bin/sh export XIM=ibus export GTK_IM_MODULE=ibus export QT_IM_MODULE=ibus export XMODIFIERS=@im=ibus export XIM_PROGRAM="ibus-daemon" export XIM_ARGS="--daemonize --xim" Following input methods/engines are available in ports: chinese/ibus-chewing Chewing engine for IBus chinese/ibus-libpinyin Intelligent Pinyin engine based on libpinyin chinese/ibus-pinyin The PinYin input method japanese/ibus-anthy Anthy engine for IBus japanese/ibus-mozc Mozc engine for IBus japanese/ibus-skk SKK engine for IBus korean/ibus-hangul Hangul engine for IBus textproc/ibus-kmfl KMFL IMEngine for IBus framework textproc/ibus-m17n m17n IM engine for IBus framework textproc/ibus-table Table based IM framework for IBus textproc/ibus-typing-booster Faster typing by context sensitive completion If ibus cannot start or the panel does not appear, please ensure that you are using up-to-date python. ===== Message from ja-ibus-mozc-2.23.2815.102.01_17: -- To activate ibus-mozc, please add the following into ~/.xinitrc, ~/.xsession, or ~/.kde4/env (for KDE4): export GTK_IM_MODULE=ibus export QT_IM_MODULE=xim export XMODIFIERS=@im=ibus /usr/local/bin/mozc start ibus-daemon -r --daemonize --xim Note that textproc/ibus-qt with IBUS option is required to make QT_IM_MODULE=ibus work. bitwalk@bitwalk-ghostbsd ~>
なにやら、ibus を有効にする方法についていろいろメッセージが表示されます。大変親切でありがたいのですが、GhostBSD のシェルは fish だし、どの情報を使えば良いのか、また、設定先のファイルをどれにすれば良いのか迷います。
最初、~/.xinitrc に ibus-mozc の設定を追加したのですが変換窓が出ませんでした。結局、~/.xprofile に以下のように vi コマンドで編集、追加(赤字部分)したところ、正常に日本語変換ができるようになりました。
bitwalk@bitwalk-ghostbsd ~> cat .xprofile #!/bin/sh setxkbmap -model pc105 -layout jp export GTK_IM_MODULE=ibus export QT_IM_MODULE=xim export XMODIFIERS=@im=ibus /usr/local/bin/mozc start ibus-daemon -r --daemonize --xim bitwalk@bitwalk-ghostbsd ~>
参考サイト [2] の情報を参考にさせていただきました。ありがとうございます。
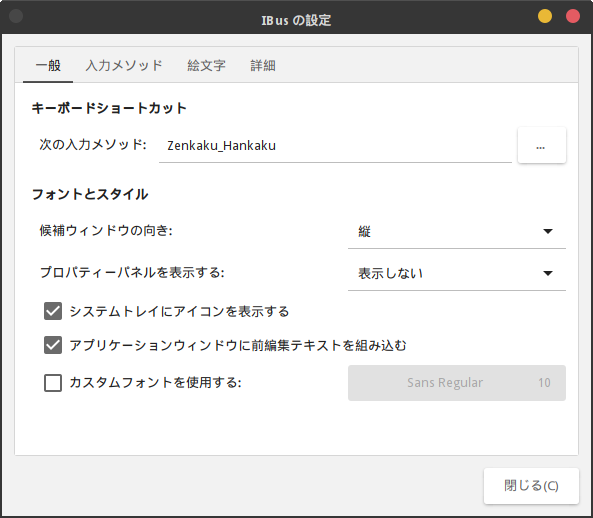
再起動後、画面上部のメニューから「システム」→「設定」→「その他」→「IBus の設定」を選んで、「一般」のタブでキーボードショートカットの次の入力メソッドを 半角/全角 キーに設定しておきます。
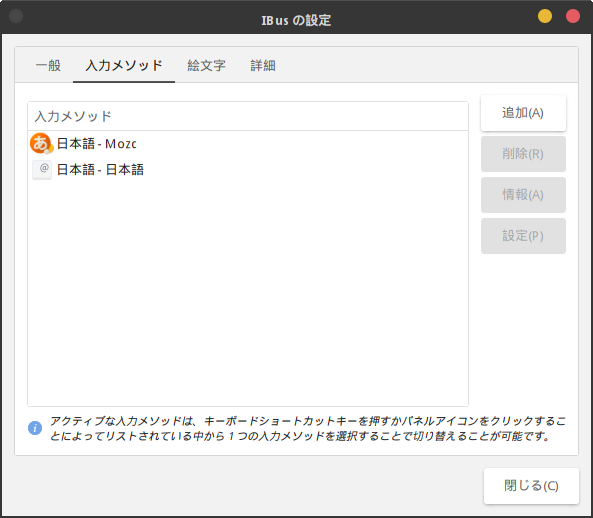
「入力メソッド」のタブで、Mozc を追加します。
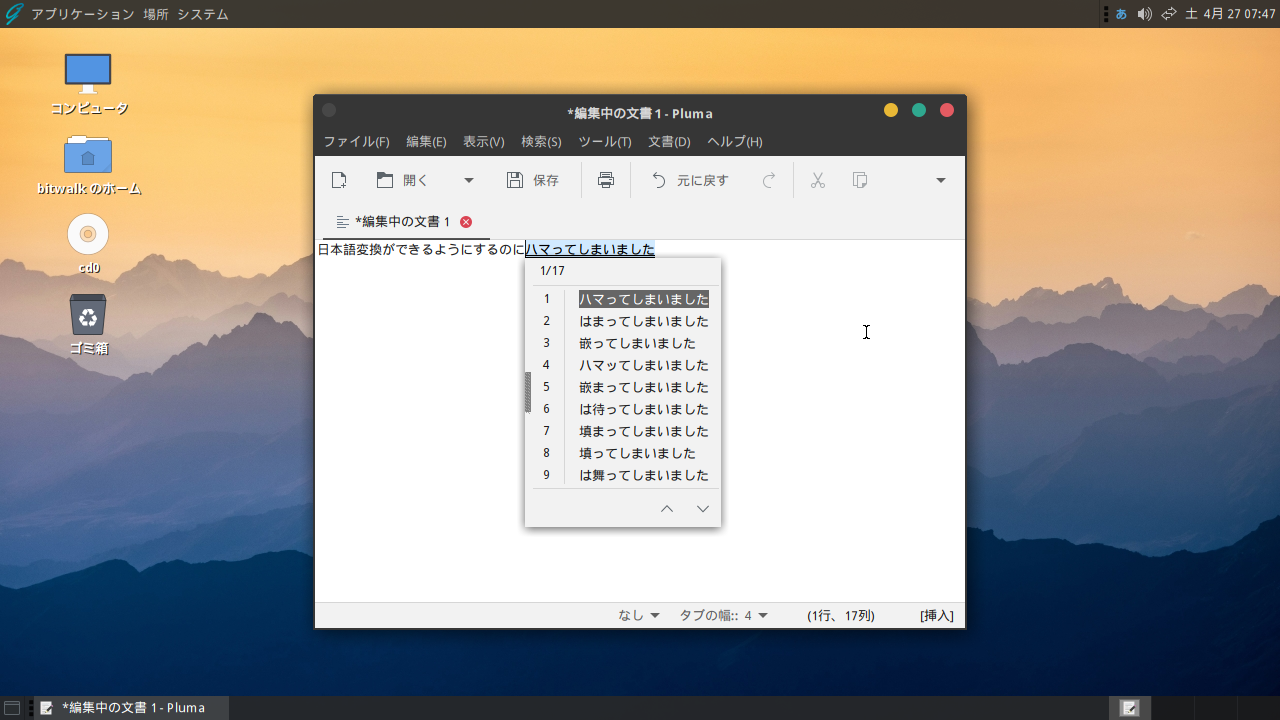
これで、日本語変換ができるようになりました。
アプリケーション
デフォルトでインストールされているアプリは控えめです。しかし、FreeBSD で利用できるパッケージは GhostBSD でも利用できるのでしょう。
アクセサリ
インターネット
オフィス
グラフィックス
サウンド&ビデオ
システムツール
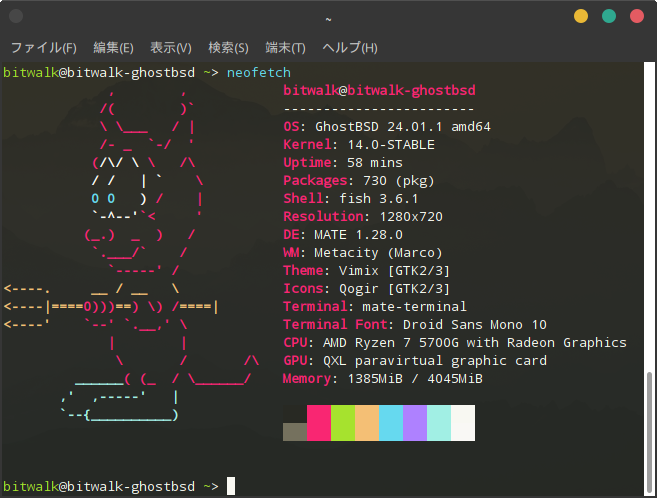
個人的には BSD 系システムで neofetch を試してみたかったのでインストールして実行してみました。
まとめ
FreeBSD 系の OS をインストールし、日本語環境を設定してパッケージをインストールする方法も判り、感激ひとしお…とはなりませんでした。なんだか Linux のディストロとの格差を感じてしまいました。
WiFi 関連のパッケージは GhostBSD のレポジトリを検索すれば出てくるので、設定は可能なのでしょうが、インストール時に Wifi が利用できないって、いまどきのノード PC へのインストールはどうするんだろうと思ってしまいます。有線ネットワークを USB ポートに変換するアダプタがあればノート PC でも使えますが、そんなアダプタを持っている人は多くないでしょう。
BSD に関して気になる記事を見つけました [4]。6年前の記事ですから、今や事態はもっと深刻なのかもしれません。
参考サイト
- A simple, elegant desktop BSD Operating System | GhostBSD
- GhostBSD 23.06.01 XFCE をインストールしました | INSUKO.NET
- GhostBSD Project
- BSDは死につつある? 一部のセキュリティ研究者はそう考えている - YAMDAS現更新履歴 [2018-01-29]
にほんブログ村

#オープンソース
